Dans ce chapitre, nous allons explorer l’apprentissage supervisé. Ce type d’apprentissage, aussi connu sous le nom d’apprentissage avec tutelle (maître), permet de déterminer la relation qui existe entre une variable explicative et une variable à expliquer (étiquette) . En d’autres termes, l’apprentissage supervisé est le processus permettant à un modèle d’apprendre, en lui fournissant des données d’entrée ainsi que des données de sortie. Cette paire d’entrée/sortie est généralement appelée «données étiquetées». Dans un cadre illustratif, pensez à un enseignant qui, connaissant la bonne réponse à une question, évaluera un élève en fonction de l’exactitude de sa réponse à cette question. Pour plus de clarification, comparons l’approche de l’apprentissage automatique à la programmation traditionnelle.
Dans la programmation traditionnelle, comme illustré dans la Figure 1, nous avons une fonction connue qui reçoit la donnée en entrée et renvoie la réponse correspondante en sortie. Par exemple, nous pouvons penser à écrire une fonction qui calcule le carré d’un nombre; si nous donnons en entrée le nombre 2, notre programme va nous renvoyer la valeur .
Figure 1:L’approche traditionnelle
L’approche de la programmation utilisée dans l’apprentissage automatique est tout à fait différente de la précédente. Dans cette dernière, nous ne connaissons pas la fonction et nous voulons donc l’approximer par une fonction en utilisant les données à notre disposition. Cette approche est donc divisée en deux phases. La première est la phase où nous entraînons notre fonction (Figure 2). Si nous revenons à notre exemple précédent, cette étape pourra consister à présenter à la fonction , plusieurs couples de nombres et leurs carrés . L’objectif ici est de trouver un moyen d’estimer la fonction "carrée" en observant uniquement les données à notre disposition.

Figure 2:L’approche apprentissage automatique
La dernière étape consiste à fournir un nouveau nombre à notre fonction , obtenue après l’étape 1, afin qu’elle prédise (approximativement) le carré de ce nombre.
Figure 3:L’approche apprentissage automatique
Dans la suite du cours, nous reviendrons beaucoup plus en détails sur les étapes ci-dessus présentées.
L’apprentissage supervisé est souvent utilisé pour deux types de problèmes: les problèmes de régression et les problèmes de classification.
Problèmes de Régression¶
Dans l’apprentissage supervisé, on parle de problèmes de régression lorsque la variable à expliquer est continue. Par exemple lorsqu’on veut prédire le prix d’une bouteille de vin sur la base de certaines variables (le pays de fabrication, qualité, le taux d’alcool, etc.). Il s’agit bel et bien d’un problème de régression.
La Régression Linéaire¶
La régression linéaire est un problème de régression pour lequel le modèle ou la fonction dépend linéairement de ses paramètres Arnaud (2013). Les différents types de régression linéaire que nous connaissons sont la régression linéaire affine, la régression linéaire polynomiale et la régression linéaire à fonctions de base radiales. Dans ce document, nous allons nous focaliser sur deux types fondamentaux de régression linéaire: la régression linéaire affine et la régression linéaire polynomiale.
La régression linéaire affine¶
Une régression linéaire de paramètre est dite affine si pour tout
avec et Le terme est appelé attribut du modèle et il sera noté par
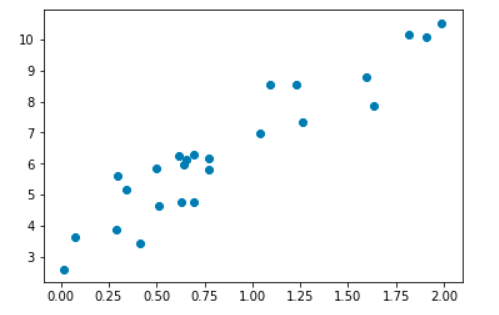
Figure 4:Représentation graphique d’un exemple de données d’entraînement
Les jeux de données représentés dans la Figure 4 forment un ensemble d’entraînement où la régression linéaire affine sera la plus appropriée.
Pour déterminer les meilleurs paramètres de la régression linéaire affine deux différentes méthodes sont utilisées à savoir: la méthode explicite et la méthode approximative.
La méthode explicite
Dans le cas de la régression linéaire affine, la méthode explicite peut-être utilisée par le biais de l’estimation du maximum de vraisemblance qui interpelle la notion de probabilité conditionnelle.
Pour être plus concret, nous allons considérer l’expression suivante:
avec .Dans cette expression, nous supposons que est la fonction que nous allons estimer à partir de son paramètre et qui nous permettra de faire nos prédictions pour chaque élément donné à partir du domaine d’entraînement. Nous noterons par comme étant la fonction estimée de .
Pour une suite de points représentant le domaine d’entraînement nous supposons que les suivent chacun une loi normale et qu’ils sont aussi indépendants et identiquement distribués (i.i.d).
Alors, nous avons et .
Déterminons le paramètre qui maximise la vraisemblance.
Dans ce cas nous avons:
Nous savons que, la fonction logarithme est une fonction strictement croissante, ce qui implique que le paramètre qui maximise la vraisemblance maximise aussi le logarithme-vraisemblance. Ainsi, en appliquant le logarithme de la vraisemblance, nous avons:
Pour chaque
Ainsi, la dérivée partielle du logarithme de la vraisemblance par rapport à est donnée par:
Alors, résoudre l’équation:
nous permettra de trouver la valeur de .
En supposant que la matrice est inversible nous avons :
Alors, vu que nous avons déterminé le paramètre , la fonction associée au paramètre , souvent appelée "hypothèse" ou "modèle" s’écrit comme
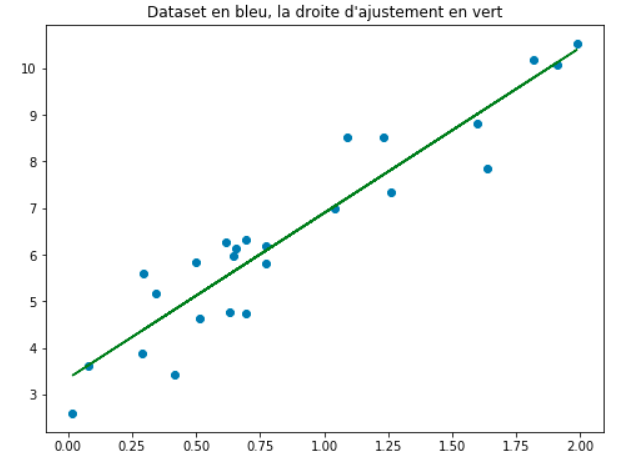
Figure 5:Représentation graphique de la fonction définie dans l’ensemble à valeur dans .
La méthode explicite nous permet d’obtenir la solution exacte de l’équation (7). Tout de même, trouver cette solution exacte est souvent très compliquée dans le cas où l’étude se fait sur un grand ensemble de jeux de données (la complexité pour trouver l’inverse dans l’équation (9) est ). Pour cela, dans ce qui suit, nous allons présenter des méthodes alternatives qui nous permettront de donner une valeur approchée à la solution exacte.
Méthodes approximatives
Dans cette partie, nous allons utiliser une méthode itérative pour estimer la valeur des paramètres de l’équation suivante:
où est le vecteur de paramètres à estimer; et les données.
La fonction de perte
La fonction de perte mesure la différence entre la valeur observée et la valeur estimée. En apprentissage automatique, l’objectif est d’optimiser la fonction de perte. Il existe différentes fonctions de perte selon le critère (ou métrique permettant d’évaluer la performance du modèle) adopté(e). Dans cette partie, nous allons utiliser l’erreur quadratique moyenne (appelé Mean Square Error (MSE) en anglais) pour définir notre fonction de perte.
L’erreur quadratique moyenne entre le observé et le prédit est donnée par:
où est la dimension des vecteurs et .
Dans le cas de la régression linéaire, cette fonction peut être réécrite comme étant une fonction de .
Par conséquent, le paramètre qui correspond à la meilleure ligne d’ajustement sera tout simplement la valeur qui minimise la fonction de perte . Pour cela, nous allons introduire une méthode la plus souvent utilisée pour minimiser une fonction (éventuellement convexe) dans l’apprentissage automatique à savoir la descente de gradient.
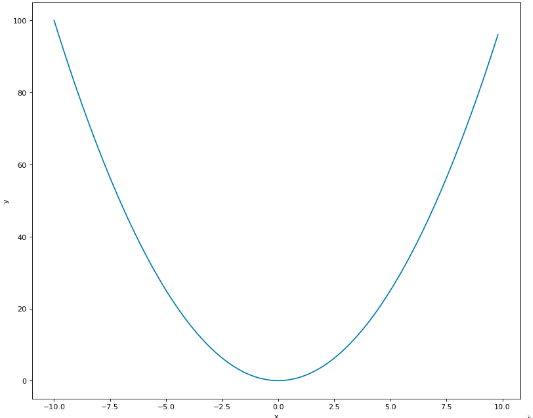
Figure 6:Représentation graphique d’une fonction convexe
Descente de gradient¶
La descente de gradient est une procédure itérative d’optimisation dans laquelle, à chaque étape, on améliore la solution en essayant de minimiser la fonction de perte considérée Bruno (2005). Elle est appliquée lorsque l’on cherche le minimum d’une fonction dont on connaît l’expression analytique, qui est dérivable, mais dont le calcul direct du minimum est difficile.
Pour entamer cette procédure, nous allons commencer par initialiser le paramètre . Ensuite, nous calculons la dérivée partielle de la fonction par rapport au paramètre donnée par:
Pour trouver les meilleurs paramètres, nous allons répéter le processus ci-dessous jusqu’à ce que la fonction de perte soit très proche ou égale à 0.
La valeur de trouvée après convergence est la valeur optimale que nous noterons par .
Alors, concernant l’exemple de la Figure 4, notre hypothèse ou modèle sera représenté par une droite d’ajustement de la même forme que celle en couleur verte sur la Figure 5. Cette droite est d’équation:
.
Implementation
Un exemple d’implementation de régression linéaire est disponibleici
La régression linéaire polynomiale¶
La régression linéaire de paramètre est dite polynomiale si pour tout
avec comme attribut le vecteur . Ainsi, deux méthodes existent pour déterminer le meilleur paramètre .
Estimation par la méthode du maximum de vraisemblance (appelée MLE: Maximum Likelihood Estimation): Suivant de manière analogique de la détermination du paramètre sur la partie précédente, la meilleure valeur du paramètre est déterminée par
Estimation par la méthode d’un posteriori maximal (appelée MAP: Maximum A Posteriori): La méthode consiste à trouver la valeur qui maximise le produit entre la vraisemblance et la distribution à priori des paramètres comme l’indique l’équation (49). Cette méthode d’estimation apparaît généralement dans un cadre bayésien. Tout comme la méthode du maximum de vraisemblance, elle peut être utilisée afin d’estimer un certain nombre de paramètres inconnus, comme les paramètres d’une densité de probabilité, reliés à un échantillon donné. La seule différence avec la méthode de maximum de vraisemblance est sa possibilité de prendre en compte un à priori non uniforme sur les paramètres à estimer. Ainsi, nous pouvons dire que l’estimateur au maximum de vraisemblance est l’estimateur MAP pour une distribution à priori uniforme.
Par le théorème de Bayes, nous pouvons obtenir le postérieur comme un produit de vraisemblance avec :
Avec et où représente la matrice identité dont la dimension est la longueur du vecteur . Ainsi, nous pouvons écrire la vraisemblance comme:
En utilisant la fonction logarithme, nous avons
Et le paramètre à estimer correspond au qui annule la dérivée partielle de par rapport à .
.
Ceci revient à déterminer le qui annule l’expression
Alors,
Cas Pratique
Les Problèmes de Classification¶
A la différence avec le problème de régression, la classification est un autre type de problème d’apprentissage supervisé où la variable à prédire est discrète (ou qualitative ou catégorique). Cette variable discrète peut être binaire (deux classes) ou multiple (multi-classe). Par exemple lorsqu’on veut catégoriser si un e-mail reçu est un ‘spam’ ou "non-spam" il s’agit bel et bien d’un problème de classification.
L’algorithme des plus proches voisins (-NN)¶
L’algorithme des plus proches voisins aussi appelé -Nearest Neighbors (-NN) en anglais est une méthode d’apprentissage supervisé utilisée pour la classification aussi bien que la régression Goodfellow et al. (2016). Il est compté parmi les plus simples algorithmes d’apprentissage automatique supervisé, facile à mettre en oeuvre et à comprendre.
Toutefois dans l’industrie, il est plus utilisé pour les problèmes de classification. Son fonctionnement se base sur le principe suivant: dis moi qui sont tes voisins, je te dirais qui tu es ...
L’objectif de cet algorithme est de déterminer la classe d’une nouvelle observation en fonction de la classe majoritaire parmi ses plus proches voisins. Donc l’algorithme est basé sur la mesure de similarité des voisins proches pour classifier une nouvelle observation .
La méthode des plus proches voisins, où représente le nombre de voisins proches est une méthode non-paramétrique. Cela signifie que l’algorithme permet de faire une classification sans faire d’hypothèse sur la fonction qui relie la variable dépendante aux variables indépendantes .
Soit l’ensemble des données ou l’échantillon d’apprentissage, défini par:
où dénote la classe de la donnée et est le vecteur représentant les variables (attributs) prédictrices de la donnée .
Supposons un nouveau point pour lequel nous voulons prédire la classe dans la quelle il doit appartenir comme indiqué dans la Figure 7.
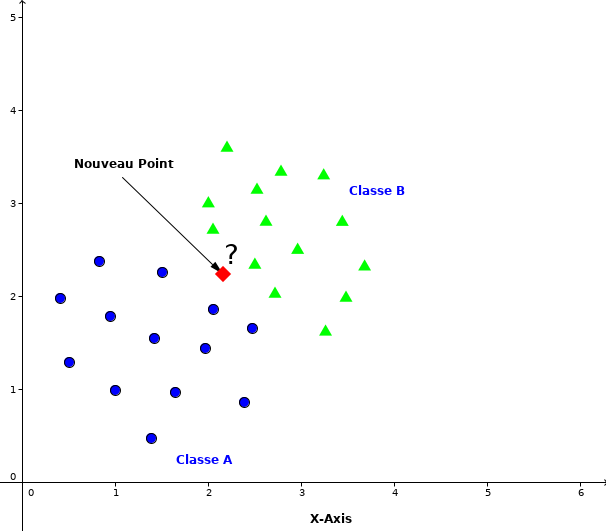
Figure 7:Classification d’un nouveau point entre deux classes
La première chose à faire est de calculer la distance entre le point avec tous les autres points. Ensuite trouver les points les plus proches de . C’est-à-dire les points dont la distance avec est minimale. Les points plus proches de dans l’échantillon d’apprentissage sont obtenus par:
Pour tout où est une fonction de distance. Et en suite la classe prédite de notée est la classe majoritairement représentée par les voisins.
Les points similaires ou les points les plus proches sont sélectionnés en utilisant une fonction de distance telle que la distance euclidienne (22), la distance de Manhattan (21) et la distance de Minkowski (23). On choisit la fonction de distance en fonction des types de données manipulées, par exemple dans le cas où les données sont quantitatives et du même type, c’est la distance euclidienne qui est utilisée.
Les points les plus proches de sont trouvés en utilisant une fonction de distance telle que la distance Euclidienne, la distance de Minkowski et la distance de Manhattan.
Algorithme¶
Soient un échantillon d’apprentissage des observations relatives à une classe et une nouvelle observation dont la classe doit être prédite. Les étapes de l’algorithme: Ainsi, l’algorithme se présente comme suit:
Choisir le paramètre , le nombre de voisins les plus proches;
Calculer la distance de la nouvelle observation avec tous les autres échantillons selon une fonction de distance choisie
Sélectionner les plus proches voisins de ;
Former la collection des étiquettes des plus proches voisins de ;
Et la classe de , est choisie d’après la majorité des plus proches voisins, c’est-à-dire
.
Répéter l’étape 2 à 5 pour chaque nouveau point à classifier.
L’algorithme Comment choisir la valeur de ? nous présente le pseudo-code de la méthode de plus proches voisins.
Comment choisir la valeur de ?¶
En générale, le choix de la valeur de dépend du jeu de données. Pour la classification binaire (en deux classes) par exemple il est préférable de choisir la valeur impaire pour éviter les votes égalitaires. Historiquement, la valeur optimale de pour la plupart de données est choisie entre 3 et 10 Shalev-Shwartz & Ben-David (2014).
Une optimale valeur de peut être sélectionnée par diverses techniques heuristiques dont la validation-croisée (que nous allons expliquer ci-dessous).
Notons que, si l’algorithme est utilisé pour la régression, c’est la moyenne (ou la médiane) des variables des plus proches observations qui sera utilisée pour la prédiction. Et dans le cas de la classification, c’est le mode des variables des plus proches observations qui servira pour la prédiction.
Validation-croisée (Cross-Validation)
La Validation-croisée (Cross-validation) est une méthode très populaire utilisée pour estimer la performance d’un algorithme. C’est une méthode statistique souvent utilisée dans des procédures d’estimation et aussi pour la sélection de modèles Chen (2019).
Son principe est le suivant :
séparer les données en données en deux échantillon (apprentissage et validation);
construire l’estimateur sur l’échantillon d’apprentissage et utiliser l’échantillon de validation pour évaluer l’erreur de prédiction;
Répéter plusieurs fois le processus et enfin faire une moyenne des erreurs de prédiction obtenues.
C’est une technique très utilisée pour le choix de meilleurs paramètres et hyperparamètres d’un modèle, par exemple pour le choix de la meilleure valeur de dans l’algorithme de plus proches voisins (-NN).
On distingue les variantes suivantes de la technique de validation-croisée:
-fold cross-validation : Partitionnement des données en sous-ensembles. Chaque sous-ensemble sert à tour de rôle d’échantillon de validation et le reste de sous-ensembles d’échantillon d’apprentissage. En pratique la valeur de varie entre 5 et 10.
Leave-one-out cross-validation: qui signifie de laisser à tour de rôle une observation comme échantillon de validation et le reste des données comme échantillon d’apprentissage. C’est un -fold validation-croisée avec , le nombre total d’observations.
Leave--out qui signifie de laisser à tour de rôle observations comme échantillon de validation et le reste des données comme échantillon d’apprentissage. C’est une -fold validation-croisée.
D’une manière générale, la procédure de partitionnement des données se présente souvent comme suit:
Les données d’apprentissage permettent de trouver un estimateur.
Les données de validation nous permettent de trouver les meilleurs paramètres du modèle.
Les données test permettent de calculer l’erreur de prédiction finale. Notons que cette méthode de validation-croisée est utilisée pour tous types d’algorithme d’apprentissage.
Les avantages de l’algorithme de -NN¶
Il est simple, facile à interpréter.
Il n’existe pas de phase d’apprentissage proprement dite comme c’est le cas pour les autres algorithmes, c’est pour cela qu’on le classifie dans le Lazy Learning.
Offre des performances très intéressantes lorsque le volume de données d’apprentissage est trop large.
Le temps d’exécution est minimum par rapport à d’autres algorithmes de classification.
Il peut être utilisé pour classification et régression.
Il ne fait pas d’hypothèse (linéaire, affines,..) sur les données.
Les limitations de l’algorithme de -NN¶
L’algorithme a plus besoin de mémoire car l’ensemble des données doivent être garder dans cette dernière pour pouvoir effectuer la prédiction d’une nouvelle observation à chaque fois.
Sensibles aux attributs non pertinents et non corrélés.
L’étape de la prédiction peur être lente dû au calcul de distance de chaque nouvelle observation avec les jeux de données en entier à chaque prédiction.
Le choix de la fonction de distance ainsi que le nombre de voisins peut ne pas être évident. C’est ainsi qu’il faut essayer plusieurs combinaisons(en utilisant la méthode de validation-croisée) pour avoir un bon résultat.
Exemple pratique¶
Ci-dessous, nous allons prendre un exemple simple pour comprendre l’intuition derrière l’algorithme de -NN. Considérons le tableau de données ci-dessous qui contient la taille (feet), l’âge (année) et le poids(en kilogramme) de 10 personnes où ID représente l’identifiant de chaque personne dans le tableau. Comme vous le remarquez le poids du ID 11 est manquant. Nous allons appliquer l’algorithme de -NN pour prédire le poids de la personne ID 11.
| ID | Taille | Âge | Poids |
|---|---|---|---|
| 1 | 5 | 45 | 77 |
| 2 | 5.11 | 26 | 47 |
| 3 | 5.6 | 30 | 55 |
| 4 | 5.9 | 34 | 59 |
| 5 | 4.8 | 40 | 72 |
| 6 | 5.8 | 36 | 60 |
| 7 | 5.3 | 19 | 40 |
| 8 | 5.8 | 28 | 60 |
| 9 | 5.5 | 23 | 45 |
| 10 | 5.6 | 32 | 58 |
| 11 | 5.5 | 38 | ? |
Données pour l’illustration
Nous pouvons représenter graphiquement les données du Paragraph en se basant sur la taille et l’âge.
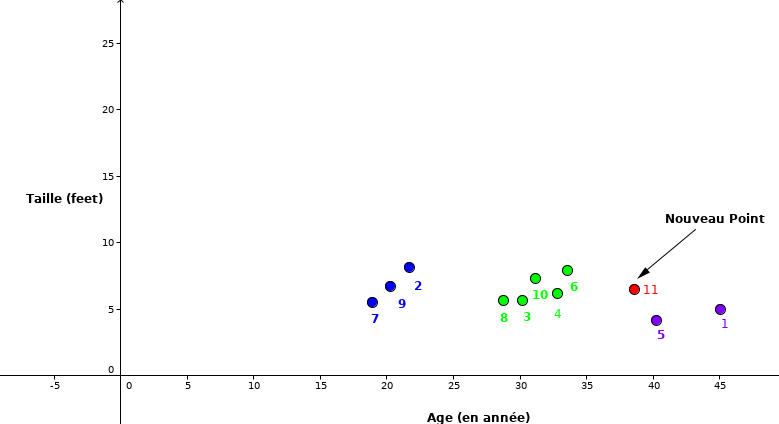
Comme nous le remarquons, le point rouge (ID 11) est notre nouvelle observation dont nous voulons prédire la classe dans laquelle il appartient.
Étape 1: Commençons par choisir le nombre des voisins les plus proche. Pour notre cas prenons .
Étape 2: Calculer la distance entre le nouveau point (rouge) avec tous les autres points
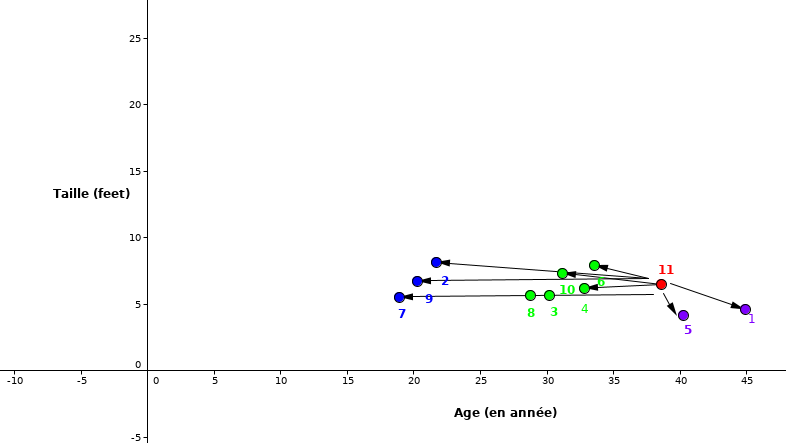
Figure 9:La distance euclidienne entre nouvelle observation et tous les autres points
Étape 3: Sélectionner les 5 plus proches voisins.
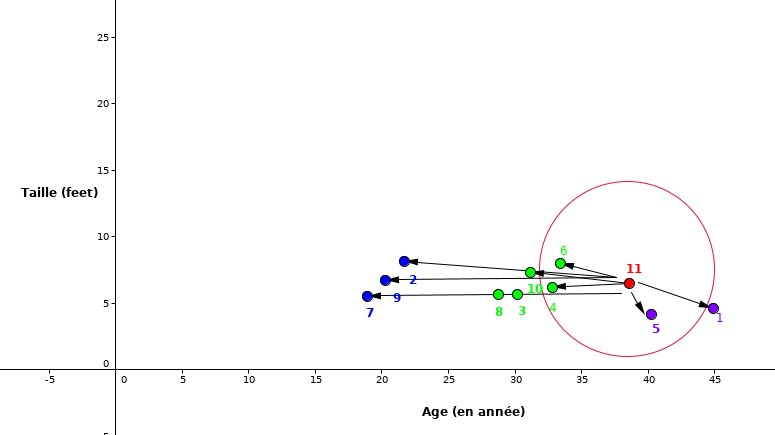
Figure 10:Sélection de 5 plus proches voisins
Étape 4: Pour la valeur de , les points les plus proches sont
Étape 5: Ainsi, comme la classe des points et 10 est majoritaire donc le point 11 se classifie dans cette classe. Et comme c’est un cas de la régression, la prédiction pour ID11 est la moyenne de ces 5 voisins les plus proches c’est-à-dire . Ainsi le poids prédit pour ID11 est .
L’algorithme du Perceptron¶
L’algorithme de perceptron est un algorithme d’apprentissage supervisé utilisé pour la classification binaire (c’est-à-dire séparant deux classes). C’est l’un des tout premier algorithme d’apprentissage supervisé et de réseau de neurones artificiels le plus simple. Le terme vient de l’unité de base dans un neurone qui s’appelle perceptron.
C’est un type de classification linéaire, c’est-à-dire que les données d’apprentissage sont séparées par une droite classées dans des catégories correspondantes de telle sorte que si la classification à deux catégories est appliquée, toutes les données sont rangées dans ces deux catégories. Dans ce cas on cherche à trouver un hyperplan qui sépare correctement les données en deux catégories. Comme nous le voyons dans la Div ci-dessous.
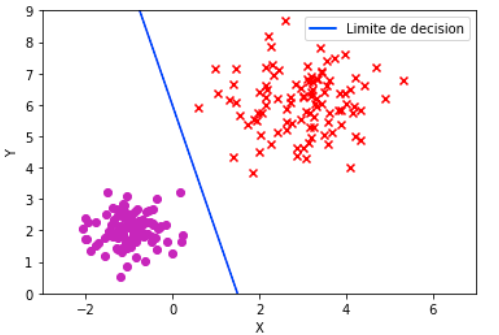
L’algorithme du perceptron
L’idée générale de l’algorithme du perceptron est d’initialiser le vecteur de poids réels au vecteur nul ou à une variable aléatoire, itérer un nombre de fois jusqu’à la convergence sur les données d’apprentissage.
Soient , un ensemble de données où est le vecteur d’entrées de dimension et l’étiquette ; un vecteur poids de dimension .
L’objectif est de trouver un hyperplan qui sépare les deux classes. Le terme est l’intercepte appelé aussi "bias term" et est le produit scalaire défini par .
C’est-à-dire apprendre le vecteur tel que:
Algorithme¶
Soient les données d’apprentissage où , et le nombre d’itérations. L’algorithme se présente comme suit:
L’avantage de l’algorithme de perceptron est sa simplicité et son efficacité de séparer linéairement les données d’apprentissage. Néanmoins, tous les hyperplans qui séparent les données sont équivalents.
L’algorithme ne peut séparer et converger vers la solution uniquement que si les données d’apprentissage sont linéairement séparables. Aussi, il n’est pas efficace quand il y a beaucoup d’attributs.
La Régression Logistique¶
La régression logistique est une méthode de classification simple mais puissante, pour les données binaires, et elle peut facilement être étendue à plusieurs classes. Considérons d’abord le modèle de régression le plus simple, correspondant à celui que nous avons vu précédemment, pour effectuer la classification. Nous le trouverons bientôt totalement insuffisant pour ce que nous voulons réaliser et il sera instructif de voir exactement pourquoi. Le modèle de la régression linéaire comme défini dans l’équation (1), peut se réécrire comme:
où est une matrice de taille et .
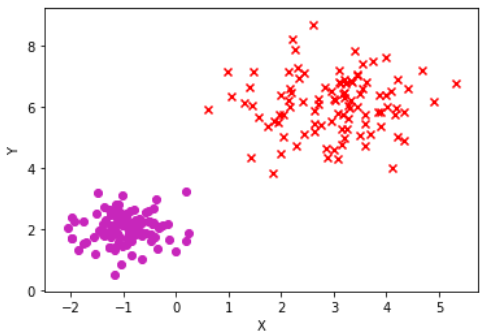
Comme dans de nombreux problèmes d’estimation de paramètres, est trouvé en minimisant certaines fonctions de pertes qui capturent à quel point notre prédiction est proche de la valeur réelle. Quand nous faisons des hypothèses sur la distribution des données, la fonction de perte est souvent en termes de vraisemblance des données. Cela signifie que le optimal est celui pour lequel les données observées ont la probabilité la plus élevée. Par exemple, la régression linéaire suppose généralement que la variable dépendante est normalement distribuée autour de la moyenne . Il peut être montré que la solution du maximum de vraisemblance est le qui minimise la somme des erreurs quadratiques (la différence entre les valeurs prédites et les valeurs correctes). Si nous essayons d’utiliser la régression linéaire pour un problème de classification (prenons l’exemple d’une classification binaire) une méthode simple serait de grouper les données de telle sorte que:
Ceci est illustré par la Figure 11.
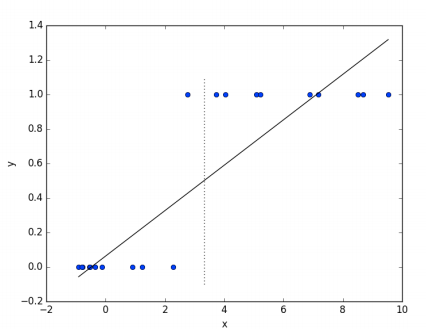
Figure 11:Régression linéaire dans le cas d’une classification binaire
La régression logistique binaire¶
La régression logistique ordinaire ou régression logistique binaire vise à expliquer une variable d’intérêt binaire (c’est-à-dire de type « oui / non » ou « vrai / faux »). Les variables explicatives qui seront introduites dans le modèle peuvent être quantitatives (l’âge, la taille, etc) ou qualitatives (le genre par exemple).
Exemple
Dans cet exemple, la variable explicative est une matrice de vecteurs colonnes où est le vecteur ‘apprendre’ qui représente le nombre d’heures d’étude de l’étudiant, et est le nombre d’heures pendant lesquelles l’étudiant dort. L’objectif est de prédire si l’étudiant va réussir à l’examen ou non, respectivement représentée par les classes 1 et 0.
| Apprendre | Dormir | Réussir | |
|---|---|---|---|
| 4.85 | 9.63 | 1 | |
| 8.62 | 3.23 | 0 | |
| 5.43 | 8.23 | 1 | |
| 9.21 | 6.34 | 0 |
Comme dans le cas de la régression linéaire, on suppose que les données suivent une fonction linéaire de la forme:
représente la variable à expliquer, est la variable explicative et un paramètre. Comme nous l’avons vu, la variable est une variable continue. Pour utiliser cette technique dans le cas d’une variable discrète (ici binaire), supposons que est la probabilité qu’un événement se réalise; alors est la probabilité de l’évènement contraire. La variable aléatoire qui prend les valeurs ‘oui’ ou ‘non’ (1,0 en langage machine) suit la loi de Bernoulli. On définit ce qu’on appelle la transformation logit donnée par l’équation suivante:
Cette transformation donne la relation entre la probabilité qu’un évenment se réalise et la combinaison linéaire des variables. Le rapport est appelé le Rapport de Côte (RC). En appliquant l’exponentielle sur cette relation on obtient:
Ce qui implique: $$\begin{align} p &=\frac{e^{\boldsymbol{\theta}^T\mathbf{x}}}{1+e^{\boldsymbol{\theta}^T\mathbf{x}}}\nonumber\
&=\frac{1}{1+e^{-\boldsymbol{\theta}^T\mathbf{x}}} \end{align}$$
Avec , la fonction définie par est appelée la fonction Sigmoïde ou logistique. Dans les lignes qui suivent, nous allons donner certaines de ses propriétés.
La fonction Sigmoïde et ses propriétés¶
Elle est définie par:
La représentation graphique de la fonction Sigmoïde est donnée par la Figure 12.
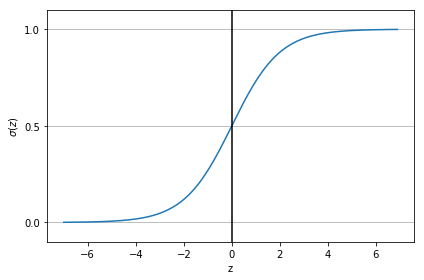
Figure 12:La fonction Sigmoïde
Une qualité importante de cette fonction est qu’elle transforme tous les nombres réels sur la plage . En régression logistique, cette transformation nous permet d’avoir une vue probabiliste qui est d’une importance cruciale pour la classification. Avec cette fonction, les nombres positifs deviennent des probabilités élevées; les nombres négatifs deviennent de faible probabilité.
Comme vous l’avez sûrement remarqué, l’algorithme de régression linéaire repose sur l’obtention d’un paramètre dit optimal. Dans la section suivante nous allons discuter sur le choix et l’obtention de la valeur .
Estimation du maximum de vraisemblance¶
Pour choisir la valeur du paramètre , on utilise la méthode du maximum de vraisemblance. La variable à expliquer est une variable binaire, i.e et la fonction Sigmoïde nous permet de projeter les résultats dans l’intervalle . Plus précisément, pour un considéré, on choisit comme étant un paramètre d’une loi de Bernoulli et ainsi, on a pour tout :
Par suite, on peut exprimer la vraisemblance:
En appliquant la fonction logarithme, on obtient le logarithme-vraisemblance donnée par l’expression suivante:
Notre objective est de trouver le paramètre qui maximise la vraisemblance:
En générale, pour trouver l’estimation du maximum de vraisemblance, nous dérivons d’abord la -vraisemblance par rapport à . Pour commencer, prenons la dérivée par rapport à une composante de , disons
Une méthode classique de trouver le optimal est de poser la dérivée pour tout et trouver la valeur exacte de qui maximise la vraisemblance. Cependant, la solution exacte n’est pas toujours facile à calculer à cause du fait que c’est une équation transcendantale (il n’y a pas de solution analytique). Par conséquent, la technique souvent utilisée pour résoudre ce problème est la méthode de la descente de gradient GD.
Ainsi en utilisant la technique de la descente de gradient, le paramètre sera mis à jour par la formule suivante, pour chaque itération:
Le paramètre est appelé taux d’apprentissage. Le paramètre obtenu à la sortie de cet algorithme maximise la log-vraisemblance.
Ainsi nous considérons un seuil 0.5 et regroupons les données comme suit:
Cas pratique¶
Régression logistique multinomiale¶
La régression logistique multinomiale est une forme généralisée de la régression logistique binaire utilisée pour estimer la probabilité quand le nombre de classe est supérieur à deux. Prenons l’exemple de reconnaissance de chiffres à partir de leur image. Cette tâche consiste à identifier une image comme l’un des éléments de l’ensemble . Dans ce cas, la fonction [1]Sigmoïde utilisée dans le cas binaire est remplacée par la [2]fonction Softmax.
La fonction Softmax et ses propriétés¶
La régression logistique multinomiale utilise une fonction Softmax pour modéliser la relation entre les variables explicatives et les probabilités de chaque classe. Elle prédit la classe qui a la probabilité la plus élevée parmi toutes les classes.
La fonction est définie par:
où est le nombre de classes.
Cette fonction prend comme entrée qui est un vecteur de dimension et produit un vecteur de même dimension de valeurs réelles entre 0 et 1.
Toutes les valeurs sont les éléments du vecteur d’entrée et peuvent prendre n’importe quelle valeur réelle. Le dénominateur de la formule (41) est le terme de normalisation qui garantit que toutes les valeurs de sortie de la fonction totaliseront 1, constituant ainsi une distribution de probabilité valide.
On peut écrire la probabilité de la classe pour sachant comme:
Estimation du maximum de vraisemblance¶
De la même façon que dans le cas de la régression binaire, nous suivrons la même procédure pour déterminer le qui maximise la vraisemblance.
L’équation (43) suppose que les instances de données ont été générées indépendamment. Ainsi, en appliquant le logarithme sur (43), nous obtenons:
Donc maximiser la équivaut à minimiser l’opposé de la donnée par l’expression suivante :
Cet opposé de la est aussi connu sous le nom de l’entropie de Shannon (cross-entropy) qui est la fonction de perte dans ce cas. Pour trouver le qui minimise cette fonction de perte, on suit la même procédure que dans le cas de la régression logistique, c’est-à-dire trouver la dérivée de la fonction de perte et appliquer l’algorithme de la descente de gradient.
En Calculant la dérivée de la fonction de perte par rapport à on a:
Maintenant on utilise l’algorithme de la descente de gradient durant le processus d’entraînement pour obtenir le optimal. À chaque itération, on met à jour chacun des paramètres par la formule suivante:
A la sortie de cette algorithme nous obtenons le paramètre optimal . Ainsi, le vecteur prédit est donné par:
Naïve Bayes¶
Dans cette sous section nous allons introduire un autre algorithme souvent utilisé dans le cadre des problèmes de classification. Cet algorithme est connu sous le nom de Naïve Bayes, naïve parce qu’il fait une simple hypothèse sur les données, celle qui suppose qu’elles sont indépendantes les une des autres, même si ceci n’est souvent pas vrai en pratique.
Les systèmes modernes populaires comme la classification des émail reçus comme spam ou non-spam sont souvent implémentés avec naïves Bayes et quelques fois leur performance est difficile à surpasser par des algorithmes sophistiqués.
Naïve Bayes fait partie des algorithmes de type génératif, qui sont différents des algorithmes vus jusque-là qui sont de type discriminatif.
L’une des grandes différences entre les algorithmes de type génératif et ceux dits discriminatifs réside dans le fait que les premiers font une hypothèse sur les données tandis que les derniers font une hypothèse sur les étiquettes (classes) .
Pour ceux qui sont familiers avec les notions mathématiques, peut être que vous vous êtes posé la question si cet algorithme a un lien avec la règle de Bayes (Naïve Bayes) ? OUI! vous avez raison car cette formule nous donne un lien entre les algorithmes de type discriminatif et ceux de type génératif.
Rappelons la formule de Bayes
Considérons le cas de la classification des émail (spam ou no-spam). Nous pouvons ré-écrire la formule précédente comme :
Avec document qui représente l’ensemble des émails, et classe leur catégorie.
Pour mieux illustrer la notion introduite dans le paragraphe précédent, réfléchissons sur un exemple pratique. Disons que vous êtes responsable d’un champ de feuille de manioc et vous voulez avoir un système qui vous alarme dès qu’une chèvre entre dans le champ. Nous supposerons (non réaliste) que dans cette contrée nous ne pouvons avoir que deux espèces d’animaux, chèvre et chien, donc nous avons deux catégories ="chèvre" et = "chien".
Comme vous l’avez sûrement appris dans ce cours, les algorithmes que nous utilisons en apprentissage automatique ne prennent en entrée que les données de type numérique. Alors nos données deviennent :
qui représente certaines caractéristiques des deux animaux, par exemple : ‘couleur’, ‘cris’, ‘vitesse’, ..., toutes ces caractéristiques ont une représentation numérique (cris : bêler=0, aboyer=1, ...).
qui prend la valeur "0" pour une chèvre et "1" pour un chien.
Dans ce contexte, un algorithme de type discriminatif va chercher à apprendre une application (mapping) de l’espace des dans l’espace des étiquettes ; en d’autres termes, ce type d’algorithmes va chercher à trouver une ligne (ou hyperplan) qui va séparer les chiens des chèvres étant données les caractéristiques () observées, tandis que celui de type génératif va se focaliser à la modélisation des caractéristiques qui distinguent un chien d’une chèvre.
Ainsi, parlons de comment nous pouvons construire un modèle de classification en utilisant Naïve Bayes.
Entraînement du Naïve Bayes (Exemple Pratique)¶
Considérons le cas de l’analyse de sentiments, sur base des commentaires de gens après avoir suivi un film. Pour raison de simplicité nous considérerons un exemple de quelques phrases et leurs classes correspondantes.
Nous commencerons par calculer le à priori pour les deux classes comme élaboré dans l’algorithme train_naive.
Comme vous l’avez remarqué, les formules que nous utilisons pour notre algorithme sont dans l’échelle logarithmique, ceci, pour raison d’éviter ce qui est connu en anglais comme underflow (quand les valeurs sont très proches de zéro au point d’être vue par l’ordinateur comme zéro), overflow (quand les valeurs sont très grandes) mais aussi pour augmenter la vitesse de calcul.
La prochaine étape consiste à définir notre vocabulaire . Le est un ensemble qui contient les mots uniques de nos données.
V = {‘tout’, ‘simplement’, ‘ennuyeux’, ‘à’, ‘fait’, ‘prévisible’, ‘et’, ‘manque’, ‘d’, ‘énergie’, ‘pas’, ‘de’, ‘surprises’, ‘très’, ‘peu’, ‘rires’, ‘intéressant’, ‘le’, ‘film’, ‘plus’, ‘amusant’, ‘l’, ‘année’}.
Nous avons au total 23 mots uniques. Nous allons par la suite, calculer les valeurs de pour les deux classes:
= ["très intéressant", "le film le plus amusant de l’année"]
= ["tout simplement ennuyeux", "tout à fait prévisible et manque d’énergie", "pas de surprises et très peu de rires"].
Calculons ensuite le logarithme de la probabilité (d’apparition) de chaque mot dans notre vocabulaire étant donné une classe particulière. En pratique, pour le calcul de , il arrive que nous rencontrons de nouveaux mots qui n’étaient pas présents dans l’étape d’entraînement, ceci conduit au fait que qui n’est pas défini. Alors pour contourner ce problème, plusieurs alternatives existent dans la littérature; dans le contexte de notre exemple, nous allons utiliser la technique appelée "add-one (Laplace) smothing" qui va transformer la formule de fournie dans l’algorithme train_naive:
En réalité comme vous l’avez peut être remarqué, l’algorithme de Naïve Bayes est simplement un comptage systématique des mots.
Notre tâche ici est de classifier la phrase "prévisible sans amusement" comme soit positive (+) ou négative (-).
| Sentiment positive (+) | Sentiment négative (-) |
|---|---|
Alors pour la phrase "prévisible sans amusement" en utilisant les formules dans l’algorithme test_naive on obtient :
Notre algorithme prédit la phrase S comme étant "négative" car comme décrit dans l’algorithme test_naive le est celui de la classe négative.
Machines à Vecteur de Support (Support Vector Machine: SVM en anglais)¶
La méthode Machines à Vecteurs de Support ou séparateurs à vaste marge est une technique très populaire en apprentissage automatique qui peut être utilisée soit pour des problèmes de régression ou de classification. Dans cette section, nous parlerons de Machines à Vecteur de Support pour la classification.
SVM est une téchnique de l’apprentissage supervisé qui consiste à séparer les données en utilisant un hyperplan (la dimension de l’hyperplan est égale à la dimension des données moins 1). L’objectif principal du SVM est de chercher les paramètres de l’hyperplan qui nous permettent d’avoir une marge maximale Shalev-Shwartz & Ben-David (2014). En contraignant la méthode SVM à avoir comme résultat un hyperplan avec une large marge, ceci peut diminuer la complexité de nos données même si la dimension des entrées est très grande. La marge est définie comme la distance entre l’hyperplan et les points qui lui sont proches (comme dans la figure ci-dessous)
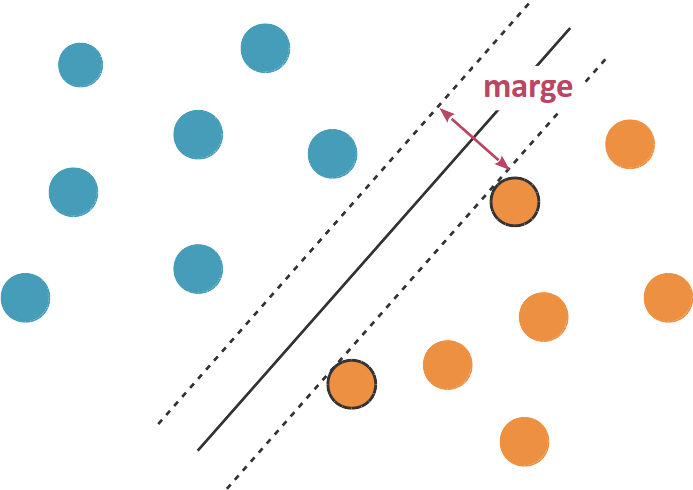
Généralement, de son algorithme découle un problème de programmation linéaire. Il existe deux variétés de Machines à Vecteurs de Support: Machines à Vecteurs de Support à marge dure et Machines à Vecteurs de Support à marge souple Shalev-Shwartz & Ben-David (2014). La Machines à Vecteurs de Support à marge souple est du même ordre (en terme d’optimisation) que celle à marge dure mais pour cette dernière, nous nous rendons à l’évidence qu’il peut y avoir d’erreurs, c’est à dire des exemples qui apparaissent entre les vecteurs de supports. Dans cette partie, nous vous présenterons uniquement la méthode de Machines à Vecteur de Support à marge dure.
Dans le cas du SVM, comme tout problème d’apprentissage supervisé les données sont representées comme suit: avec , Alpaydin (2020)Goodfellow et al. (2016).
La Figure 14 nous présente uniquement le cas où nous sommes en présence de deux classes -1 et 1, mais la méthode peut facilement être généralisée dans le cas de plusieurs classes.

Comme illustré dans la Figure 14, la forme générale de l’hyperplan est .
Dans ce cas, la marge représente les distances entre les droites et à l’hyperplan. Les points qui sont respectivement sur et sont appelés vecteurs de supports, ce sont des points les plus proche de l’hyperplan.
Note: Les données représentées dans la Figure 14 sont linéairement séparables.
Dans le cas où cette condition n’est pas satisfaite, nous utiliserons des méthodes un peu plus avancées à l’instar de la méthode à noyaux (Kernel methods en anglais) qui vous sera présentée dans le chapitre Les méthodes du noyau (Kernel methods).
Dans ce qui suit, nous présentons la formulation primale de Machines à Vecteur de Support.
Considérons une observation sur un vecteur de support. Alors, la marge est donnée par:
Comme , alors (57) devient :
Le problème d’optimisation qui découle de SVM est de maximiser la marge de telle sorte que . En d’autres termes, il s’agit de résoudre Shalev-Shwartz & Ben-David (2014):
Ceci est équivalent à trouver et qui minimisent:
avec les contraintes:
Pour résoudre le problème d’optimisation précédent (60), nous allons utiliser la méthode de Lagrange où le Lagrangien est donné par:
est quadratique et convexe en . Son minimum est donné par:
est affine en . Il est clair que, lorsque l’on a:
le minimum de existe et est fini, dans le cas contraire, cette fonction n’admettra pas de minimum car il explosera à l’infini.
Le problème d’optimisation correspondant au SVM peut être aussi résolu en utilisant la formulation duale.
Le Lagrangien de la formulation duale est donné par:
Donc le problème réciproque consiste à maximiser sous la contrainte où représente le multiplicateur de Lagrange. La maximisation de (65) peut être aussi réformulée de la manière suivante:
Le problème (66) peut aussi être écrit sous la forme matricielle:
ce qui est équivalent à:
avec
qui représente le terme quadratique et le terme de linéarité.
Note: Les contraintes correspondant à la formulation duale sont linéaires par rapport à
Pour résoudre le problème duale, nous allons utiliser la programmation quadratique ayant comme coefficients les termes et , quadratique et linéaire, respectivement.
La matrice , est une matrice d’ordre . Quand le nombre d’exemples est très élevé, il devient très coûteux de travailler avec elle.
Des valeurs de obtenues en utilisant la programmation quadratique, nous pouvons déduire en se référant à l’équation (63). , implique est un vecteur à support (VS). Cela revient à écrire comme:
Par contre, pour obtenir , nous utilisons le faite que pour tout vecteur à support : .
Les deux formulations (la formulation primale et la formulation duale) correspondante au modèle machines à vecteurs de support sont très importantes , il y a des circonstances qu’une formulation est préférable à l’autre. Par exemple, la formulation primale est utilisée lorsque la taille de l’échantillon , est négligeable par rapport à sa dimension ().
Pour la résolution des formulations correspondant à la Machine à Vecteur de Support, puisqu’elles correspondent à une programmation linéaire, on pourrait utiliser les packages d’optimisation de Sklearn de Python.
Conclusion¶
Dans ce chapitre, nous avons parlé de l’apprentissage supervisé pour les problèmes de régression et de classification. Nous pouvons retenir qu’en ce qui concerne l’apprentissage supervisé, ses algorithmes pourront être classés en deux grandes catégories: les algorithmes de type génératif et ceux de type discriminatoire. Les algorithmes génératifs comprennent par exemple, Naïves Bayes et ceux discriminatoires, la régression logistique. Il n’existe pas une formule ou une méthode standard pour le choix d’un algorithme, généralement on procéde par expérimentation. Cependant, il existe des méthodes avantageuses par rapport à d’autres; par exemple pour des problèmes faisant recours aux données streaming, on préfère utiliser l’algorithme de KNN.
Parfois les données à notre disposition n’ont pas d’étiquettes; dans ce cas nous devons nous référer à d’autres techniques pour pouvoir effectuer soit la régression, soit la classification. Plus de détails seront donnés dans le chapitre Apprentissage Non-Supervisé.
https://fr.wikipedia.org/wiki/Sigmoïde_(math%C3%A9matiques)
- Arnaud, G. (2013). Régression linéaire.
- Bruno, B. (2005). Descente de gradient.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
- Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding machine learning: From theory to algorithms. Cambridge university press.
- Chen, L.-P. (2019). Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar: Foundations of machine learning. Springer.
- Alpaydin, E. (2020). Introduction to Machine Learning, (Adaptive Computation and Machine Learning series). MIT Press, Cambridge, MA.