Motivations et Rappels¶
Motivations¶
La plupart du temps, en apprentissage automatique, les difficultés que nous rencontrons ne se situent pas dans l’exécution ou l’implémentation des modèles et algorithmes de prédictions, mais dans l’adaptation de ces derniers aux données soumises à notre analyse.
Les données sont généralement classifiées en deux catégories à savoir:
Les données c’est-à-dire les données qui peuvent facilement être séparées en groupes (ou classes) d’échantillons qui ont des propriétés similaires, mesurées sur des observations, à l’aide d’un hyperplan, parfaitement construit via un calcul de décision par combinaison linéaire des échantillons.
Les données sont totalement le contraire de celles dites linéairement séparables car ici, il n’est pas évident de manière directe séparer les données en groupes (ou classes) d’échantillons qui ont des propriétés similaires, à l’aide d’un hyperplan (en haute dimension).
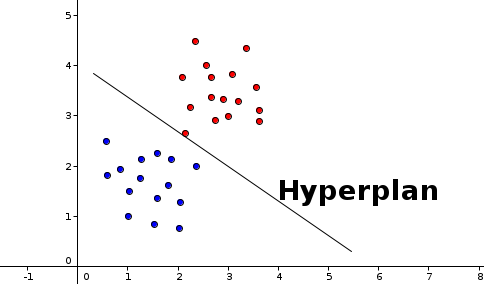
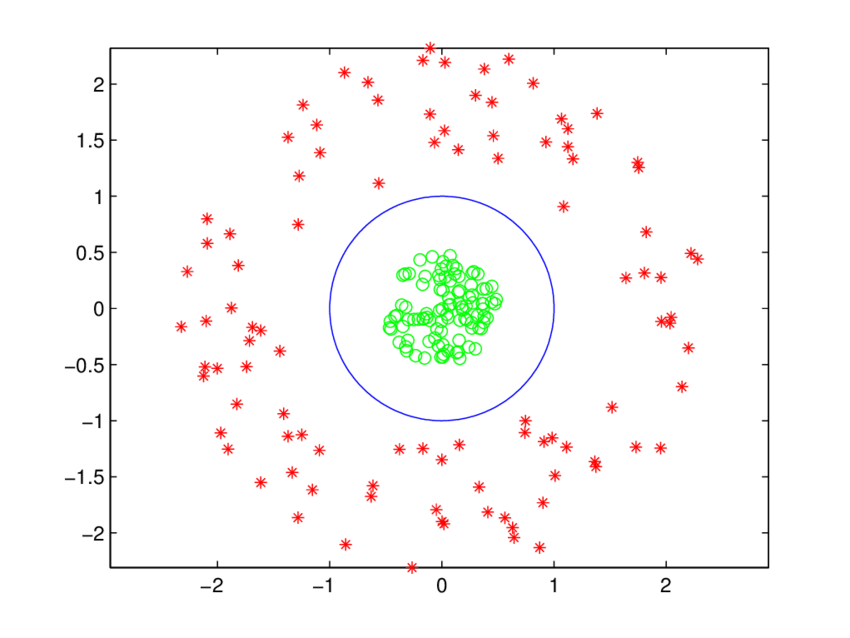
À cet effet, il est souvent plus facile de résoudre les problèmes aux données linéairement séparables que ceux qui ne le sont pas, ceci en utilisant les techniques et méthodes présentées dans les chapitres 3 et 4. Cependant, il se trouve que dans la majeur partie des problèmes réels et du vécu quotidien, les données souvent manipulées sont rarement linéairement séparables, car elles sont plus compliquées, ce qui rend plus complexes l’analyse et les prédictions via les modèles basiques de l’apprentissage automatique. D’où l’intérêt de ce chapitre sur les méthodes du noyau.
Le but de ce chapitre est d’étendre les notions vues dans les chapitres précédents et les techniques de l’apprentissage de la statistique linéaire, à un monde réel, plus complexe, mieux structuré et en dimension plus élevée. Nous allons nous appuyer sur les méthodes mathématiques liées aux outils de modélisation pratique et algorithmes ou modèles de prédiction déjà bien connus en apprentissage automatique.
Rappels¶
Espace de Hilbert¶
Il y a au moins deux raisons profondes qui expliquent l’importance et l’omniprésence des espaces de Hilbert dans les mathématiques.
Premièrement, ils apparaissent comme généralisation naturelle des espaces euclidiens de dimension finie (par exemple, le plan ou l’espace ). Ils bénéficient des propriétés familières telles que le produit scalaire, l’orthogonalité, les projections (orthogonales), le théorème de Pythagore, etc.
Crucialement, on demande que les espaces de Hilbert abstraits soient complets pour la topologie qui dérive de leur norme. Cette condition de complétude est importante, et on la requiert afin que les constructions géométriques et les passages à la limite se passent aussi bien en dimension infinie qu’en dimension finie, et aussi, afin qu’il existe des bases orthonormées, de cardinal infini, le long desquelles on puisse décomposer chaque vecteur.
Définitions
Soit un espace vectoriel normé sur ou .
La suite est dite de si et seulement si,
, , , ,
De façon équivalente:
, , ,
Remarque: La suite de est dite de Cauchy si et seulement si:
Propriétés:
Toute suite de Cauchy est bornée.
Toute suite convergente est de Cauchy.
Un espace vectoriel normé est dit si et seulement si toute suite de Cauchy de est convergente. Un espace vectoriel normé complet est dit un . Un ensemble est dite complet si toute suite de Cauchy d’éléments de converge dans .
Définition: (Espace de Hilbert)
Un espace de Hilbert est un espace vectoriel réel ou complexe muni d’un produit scalaire et qui est pour la norme associée.
Quelques propriétés et caractéristiques des espaces de Hilbert¶
Sur un ensemble , on peut définir une topologie comme un ensemble de parties de vérifiant les propriétés suivantes:
et l’ensemble vide appartiennent à ;
est stable par intersection finie: Pour tout , , ;
est stable par la réunion quelconque: Pour tout ensemble (fini ou infini) d’indices, pour tout .
Alors par définition, un sous-ensemble de est un de pour la topologie si et seulement si appartient à (il en résulte que la topologie peut être définie comme l’ensemble des ouverts de selon ).
Définition: (Espace fermé)
Dans un espace topologique , un est un sous-ensemble de dont le complémentaire est un ouvert.
Définition: (Produit hermitien)
Un produit hermitien sur un -espace vectoriel est une application:
est anti-linéaire; linéaire.
(en particulier est réel).
si .
Proposition:
Un sous-espace fermé d’un espace de Hibert est un espace de Hilbert (pour la restriction du produit hermitien).
Géométrie dans un espace de Hilbert:
Inégalité de Cauchy-Schwarz: l’inégalité de Cauchy-Schwarz s’écrit:
L’égalité de la médiane:
.
Théorème:
Une application linéaire entre deux espaces de Hilbert, , est continue si et seulement si il existe une constante telle que pour tout de on a:
.
Si est un sous-espace quelconque de , on pose:
.
Si est un sous-espace , alors
.
Soit une forme continue sur un espace de Hilbert. Il existe un unique vecteur tel que:
.
On peut supposer . On choisit un vecteur unitaire orthogonal à . ( existe car et ).
On a alors , donc . On vérifie alors que , pour puis . C’est donc vrai pour tout , et la proposition est vérifié avec:
Noyaux et espaces de Hilbert à noyau reproduisant (RKHS)¶
Pour cette partie, nous représentons les données d’entrée par une matrice carrée définie par , où est un espace pris arbitrairement, une matrice de noyau et une fonction symétrique définie par
et ,
Une notion assez importante à révéler ici est la qui est donnée par:
, la matrice de noyau est définie positive, c’est-à-dire,
,
Les conditions de positivité et symétricité sont très importantes pour définir un kernel valide.
Exemple: , . Pour tout et , nous avons , ceci implique que est symétrique. De plus, , . Donc, puisque est positif et symétrique, alors c’est un kernel valide.
Un noyau est défini positif si et seulement s’il existe un espace de Hilbert et un ‘feature map’ tels que:
Opérations sur les noyaux définis positifs (d.p)
Structure de cône:
noyau d.p, noyau d.p.
noyau d.p. noyau d.p.
noyaux d.p. noyau d.p.
Noyau polynomial en dimension p>1
Le noyau polynomial en dimension , est donné par l’expression suivante:
Il y a deux possibilités d’expandre cette expression et ceci peut se faire de la façon suivante:
contient tous les monômes (avec des poids) avec
Dimension de (grand!).
Noyaux invariants par translation
Les noyaux invariants par translation sont de la forme :
Proposition:
est défini positif si et seulement si la transformée de Fourier de est positive ou nulle pour tout
Exemple: Noyau Gaussien:
Avant de continuer plus loin, faisons le point sur tout ce que nous avons vu jusqu’ici:
On a vu qu’un noyau défini positif est équivalent à une matrice symétrique semi-définie positive.
Lorsque la fonction (‘feature map’) est connue au préalable (comme présenté dans le théorème Paragraph ) le noyaux s’exprime explicitement de la forme
Contrairement, le noyaux sera déduite implicitement (exemple: Noyau Gaussien).
Deux théories permettent de construire la fonction :
Espaces de Hilbert à noyaux reproduisant (RKHS).
Noyaux de Mercer.
Soit un ensemble quelconque et un sous-espace de l’espace des fonctions de dans , qui est muni d’un produit scalaire Hilbertien.
est un RKHS avec noyau reproduisant si et seulement si:
contient toutes les fonctions de la forme:
et ,
(c’est-à-dire correspond au ‘Dirac’ en ).
s’il existe un noyau reproduisant, il est unique.
un noyau reproduisant existe si et seulement , la forme linéaire est continue.
Si est un noyau reproduisant, alors est un noyau défini positif.
Si est un noyau défini positif, alors est un noyau reproduisant (pour un certain RKHS ).
Construction du RKHS pour un noyau d.p.
Dans cette section nous donnons les étapes pour la construction du noyau sur un RKHS:
Construction de l’ensemble de combinaisons linéaires finies de fonctions ,
Définition du produit scalaire sur de la manière suivante:
Interprétation de la norme
La norme contrôle les variations de .
est une fonction lipschitzienne c’est a dire:
La norme du RKHS contrôle la constante de Lipschitz de pour la métrique
Noyaux de Mercer
Construction semi-explicite d’un ‘feature space’ égale à l’ensemble des suites de réels.
Hypothèses: espace métrique compact muni d’une mesure , noyau noyau d.p. continu.
Théorème de Mercer: il existe une base Hilbertienne de de fonctions continues ( est une suite décroissante () tendant vers zéros, telle que:
,
Faisons un point de ce que nous avons vu jusqu’ici:
Resume
Noyaux définis positifs = produits scalaires de ‘features’
Noyaux de Mercer: ‘feature map’ obtenu à partir de l’opérateur de convolution.
RKHS: construction explicite sans hypothèses.
Interprétation de la norme du RKHS en terme de régularité des fonctions.
Noyaux classiques: linéaires, polynomiaux, Gaussiens.
Le Noyau: définitions et propriétés¶
Méthodes à noyaux générales¶
Astuce du noyau (Kernel Trick) et théorème du représentant¶
Astuce du noyau
Un noyau défini positif correspond à des “features” potentiellement nombreux et souvent implicites;
Principe: tout algorithme sur des vecteurs de dimension finie n’utilisant que des produits scalaires peut être utilisé en remplaçant le produit scalaire par n’importe quel noyau défini positif;
Il existe de nombreuses applications pour les astuces du noyau.
Soient un ensemble, un noyau d.p., et son RKHS associé, et , points dans .
Soit strictement croissante par rapport à la dernière variable
Toute solution du problème d’optimisation suivant:
s’écrit de la forme
De manière classique on a:
Ridge regression (Régression de Ridge), Kernel ridge regression¶
Ridge regression
L’algorithme le plus élémentaire qui peut être kernelisé est probablement le Ridge regression. Ici, l’idée est de trouver une fonction linéaire qui modélise les dépendances entre les covariables et les variables de réponse , toutes deux continues. La manière classique de le faire est de minimiser le coût quadratique:
Cependant, si nous allons travailler dans l’espace des fonctionnalités (‘features space’), où nous remplaçons , il existe un danger évident que nous sur-ajustions (overfitting). Par conséquent, nous devons régulariser.
Un moyen simple mais efficace de régulariser est de pénaliser la norme de . Ceci est parfois appelé «perte de poids» (‘weight decay’). Il reste à déterminer comment choisir . L’algorithme le plus utilisé consiste à utiliser des estimations de validation croisée (‘cross-validation’) ou de non-participation (‘leave-one-out estimates’). La fonction de coût total devient donc,
qui doit être minimisé. Prendre des dérivées et les assimiler à zéro donne,
Kernel ridge regression
Nous remplaçons maintenant tous les cas de données par leur vecteur de caractéristiques: . Dans ce cas, le nombre de dimensions peut être bien supérieur, voire infiniment supérieur, au nombre de cas de données. Il y a une astuce qui nous permet d’effectuer l’inverse ci-dessus dans le plus petit espace des deux possibilités, soit la dimension de l’espace des fonctionnalités, soit le nombre de cas de données. L’astuce est donnée par l’identité suivante:
Notez maintenant que si n’est pas carrée, l’inverse est effectué dans des espaces de dimensionnalité différente. Pour appliquer cela à notre cas, nous définissons et . La solution est alors donnée par:
Cette équation peut être réécrite comme suit:
avec
C’est une équation qui sera un thème récurrent et qui peut être interprétée comme: La solution doit se situer dans l’étendue des cas de données, même si la dimensionnalité de l’espace d’entités est beaucoup plus grande que le nombre de cas de données. Intuitivement, cet algorithme est linéaire dans l’espace des fonctionnalités (‘features space’).
Nous devons enfin montrer que nous n’avons jamais réellement besoin d’accéder aux vecteurs de caractéristiques, qui pourraient être infiniment longs (ce qui serait plutôt peu pratique). Ce dont nous avons besoin en pratique, c’est de la valeur prédite pour un nouveau point de test, x. Ceci est calculé en le projetant sur la solution ,
où
Le message important ici est bien sûr que nous n’avons besoin que d’accéder au noyau .
Nous pouvons maintenant ajouter un biais à toute l’histoire en ajoutant une autre caractéristique constante à . La valeur de représente alors le biais puisque,
En récapitulatif, reformulons tout ceci sous un problème d’optimisation:
Considérons les données , un noyau défini positif , et
En utilisant la méthode des moindres carrés on a la formulation suivante:
Théorème du représentant implique que
Ceci est équivalent à:
La solution est égale à , avec
Cette solution est unique!
Méthodes à noyaux et optimisation convexe¶
Rappels d’optimisation convexe¶
Un problème d’optimisation de manière générale consiste à minimiser (ou maximiser) une fonction objectif qui est soit soumise à des contraintes d’égalités et/ou des contraintes d’inégalités. Dans le cas où nous avons une fonction objectif convexe, des contraintes d’inégalités convexes et contraintes d’égalité affines, nous sommes en présence d’un problème d’optimisation convexe.
Le problème général est défini par:
Avec des fonctions quelconques, et le minimum global.
Pour résoudre le problème d’optimisation (10), nous calculons sa dérivée et l’égalons à zèro. Cependant, lorsque les contraintes (d’égalité et d’inégalité ) sont nombreuses, il dévient complexe de le résoudre via cette technique d’égalisation de la dérivée a zéro. C’est la raison pour laquelle il est préférable d’utiliser la méthode de Lagrange afin de résoudre ce type problème dans un sens plus général. A cet effet, appliquons cette méthode au problème d’optimisation (10) énoncé plus haut.
En effet, le Lagrangien du problème (10) est donné par:
avec , les coefficients du Lagrangien.
La fonction duale associée est la suivante:
On a donc le problème dual (toujours concave):
On pose le maximum global du problème dual
On parle de dualité faible (toujours vraie) si
On parle de dualité forte, i.e si:
sont affines, sont convexes, et est convexe
Conditions de Slater (il existe une solution pour laquelle les contraintes d’inégalités sont strictes) est satisfaite.
Conditions nécessaires et suffisantes d’optimalité:
minimises
"complementary slackness": ,
Exemples de noyaux¶
Dans cette section, nous allons présenter quelques exemples de méthodes à noyau fréquemment utilisées en apprentissage automatique.
Noyau linéaire¶
Le noyau linéaire est le plus simple et son équation est la suivante:
Noyau polynomial¶
Ce noyau est beaucoup utilisé dans le traitement d’image et il est donné par l’équation suivante:
Dans le cas où , nous retrouvons un Noyau linéaire ()
Noyau de Laplace RBF¶
C’est un noyau à usage général; utilisé lorsqu’il n’y a aucune connaissance préalable sur les données. La formule est:
Noyau Gaussien¶
C’est un noyau à usage général; utilisé lorsqu’il n’y a aucune connaissance préalable sur les données. La formule est la suivante:
Noyau hyperbolique tangent (Noyau Sigmoid)¶
Il est généralement utilisé dans les réseaux de neurones. Son expression est la suivante:
,
pour certaines (pas toutes) valeurs de , et .