Introduction et Motivations¶
Dans le chapitre précedent, nous avons discuté des notions d’apprentissage supervisé. Dans ce type d’apprentissage, on a considéré des données étiquettées de la forme où l’objectif consiste à trouver une modélisation telle qu’on ait l’approximation , pour tout . Cependant, il est important de se demander ce qu’il en est du cas où l’on n’a pas d’étiquettes. En effet, d’après quelques médias, il y a plus d’appareils photos que d’êtres humains, donc il y a une gigantesque quantité de données images dans le monde entier. On a aussi tant de données textes, et autres. Étiqueter toutes ces données est une tâche difficile. Pourtant, il y a certains types d’apprentissages qu’on peut effectuer sur de telles données. C’est ce qu’on appelle apprentissage non supervisé.
L’apprentissage non supervisé est un type d’apprentissage automatique pour lequel les donneés utilisées ne sont pas étiquettées. L’objectif de l’apprentissage est donc de découvrir les structures sous-jacentes à ces données. Un tel type d’apprentissage comprend des méthodes comme -moyennes, le regroupement hiérarchique, les réduction de dimensions, ainsi que d’autres méthodes plus avancées dans les cas où ces données ne peuvent pas être linéarement separées (ce qui est souvent le cas en pratique). Ces méthodes ont d’importantes applications à savoir: les systèmes de recommandations, segmentation du marché, détection d’anomalies, imagèrie médicales, etc.
Dans un premier temps, nous allons voir quelques algorithmes d’apprentissage non supervisé, commençant par les algorithmes de régroupement (-moyennes, regroupement hiérarchique), puis ceux de réduction de dimensions (Analyse en composantes principales et positionnement multidimensionnel), et nous allons finir par quelques applications de ces algorithmes.
Les algorithmes de l’apprentissage non supervisé¶
Les algorithmes de l’apprentissage non supervisé sont principalement divisés en deux grands groupes, les algorithmes de partitionnement et les algorithmes de réduction de dimension. Dans ce qui suit, nous présenterons respectivement l’algorithme de partitionnement qui est le -moyennes et les algorithmes de réduction: le positionnement multidimensionnel, et l’analyse à composantes principales. Nous devons noter que les algorithmes les plus populaires de l’apprentissage non supervisé sont le -moyennes et l’analyse en composantes principales.
Algorithmes de Partitionnement.¶
-moyennes¶
Dans une optique de regroupement des données en différentes catégories ou classes représentant les différents types de données, il est nécessaire d’utiliser des algorithmes spécifiques à l’instar de l’algorithme des K-moyennes. En effet, imaginons que nous avons un ensemble de données que nous souhaitons partitionner en trois catégories. Ces données présentent des catégories différentes et peuvent être regroupées selon leur similitude tel que décrite par la Figure 1.
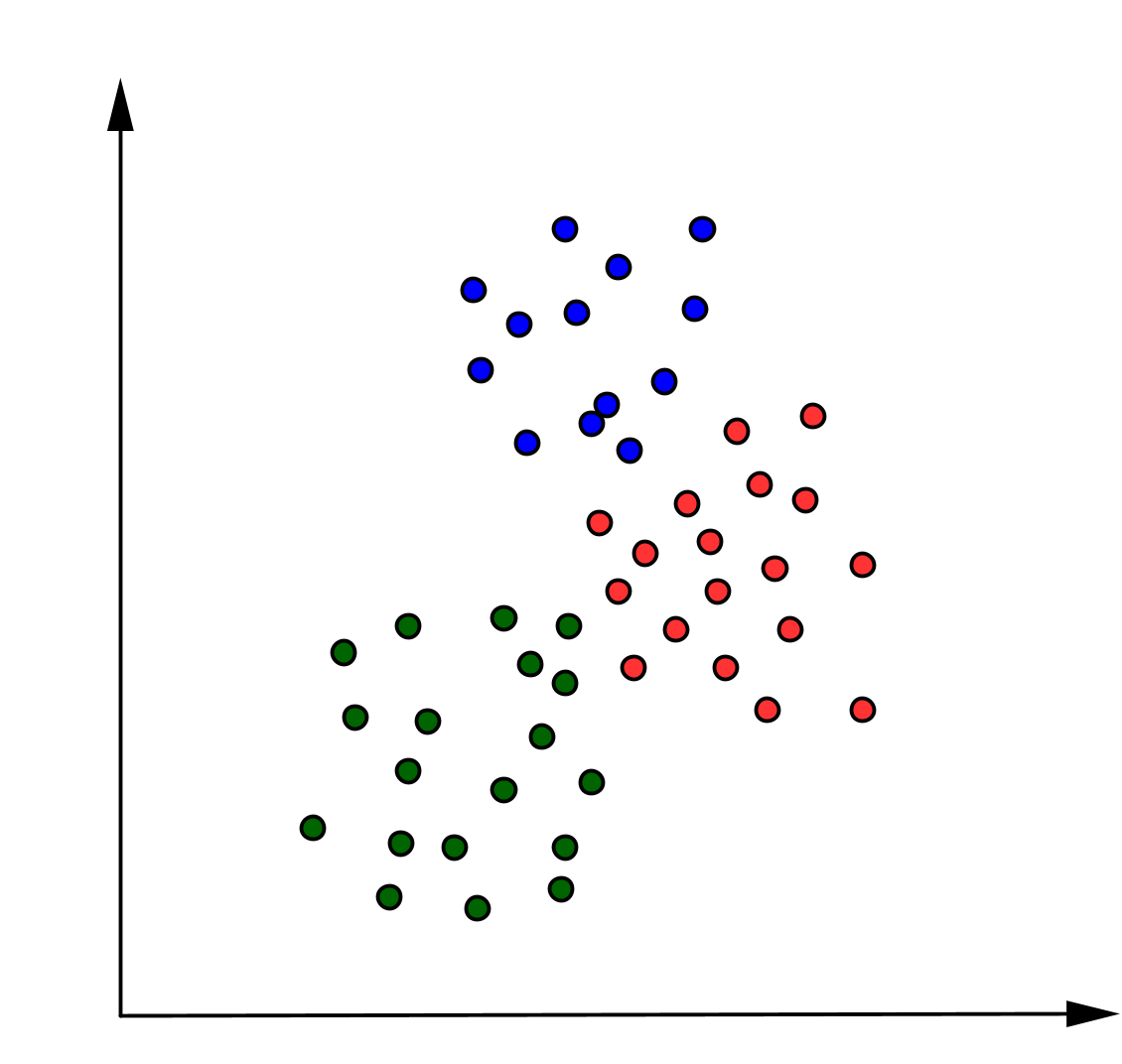
Figure 1:Représentation des données partitionnées en trois catégories
Idéalement l’intuition humaine peut nous permettre de détecter les regroupements pour le cas des données simples. Mais alors, est-il possible de demander à la machine si elle peut le faire à notre place, c’est -à-dire regrouper selon les trois catégories réquises.
K-moyennes est une méthode qui permet de regrouper les données en fonction du nombre de groupes qui lui a été recommandé. Elle comporte plusieurs étapes, à savoir:
Étape 1: Sélectionner le nombre de groupe dont nous souhaitons identifier dans les données. Celui-ci représente le "" dans l’expression -moyen. Dans notre cas par exemple car nous souhaitons regrouper en groupe de 3. Notons aussi que est un paramètre qui n’est pas directement rélié aux données.
Étape 2: Sélectionner aléatoirement 3 points différents dans nos données qui constitueront nos centroïde (regroupement initial).
Étape 3: Mesurer la distance entre chaque point du données et nos 3 points initiaux (centroïde).
Étape 4: Assigner à chaque point le regroupement correspondant au centroïde le plus proche.
Étape 5: Calculer la moyenne de chaque regroupement (mise à jour de centroïde)
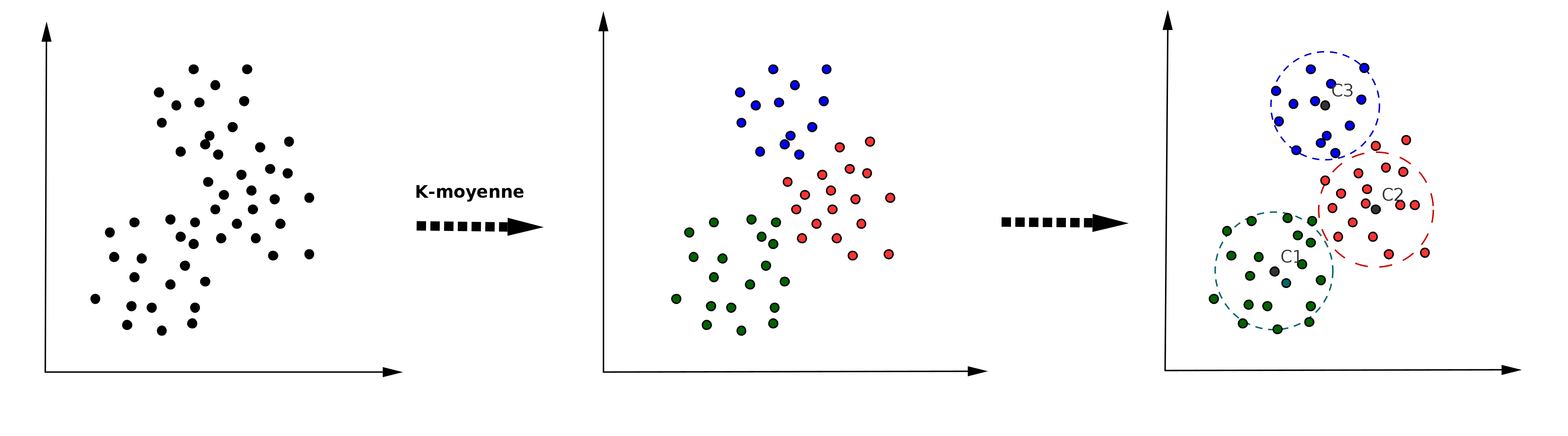
Figure 2:Application des K-moyennes
Comment choisir la valeur de ?¶
En fonction des données, nous pouvons déterminer intuitivement la valeur de .
Nous pouvons également essayer différentes valeurs de en commençant par exemple par (ceci n’étant pas conseillé ), =2, =3, etc.
Remarque¶
Il peut arriver que nos données soient complexes, de ce fait, nous devons utiliser des méthodes plus complexes que nous ne développerons pas dans cette partie, comme l’algorithme du Kernel -moyennes.
K-moyennes: Algorithme¶
L’algorithme moyennes est un algorithme itératif qui essaie de partitionner l’ensemble de données en sous-groupes distincts non chevauchant prédéfinis ( i.e chaque point de données appartient à un seul groupe). Il essaie de rendre les points de données intra-groupe aussi similaires que possible tout en gardant les regroupements aussi différents (loin) que possible. Il attribue des points de données à un regroupement de telle sorte que la somme de la distance au carré entre les points de données et le centre de gravité du regroupement (moyenne arithmétique de tous les points de données appartenant à ce regroupement) soit minimale. Moins nous avons de variation au sein des regroupements, plus les points de données sont homogènes (similaires) au sein du même regroupement. L’algorithme des -moyennes peut être décrit tel que suit:
Spécifier le nombre de regroupements .
Initialiser les centres de gravité en sélectionnant au hasard points de données pour les centres de gravité sans remplacement.
Calculer la somme de la distance au carré entre les points de données et tous les centres de gravité.
Attribuer chaque point de données au regroupement le plus proche (centroïde).
Calculer les centres de gravité des regroupements en prenant la moyenne de tous les points de données appartenant à chaque groupe.
Répéter les étapes jusqu’à ce qu’il n’y ait aucune modification des centres de gravité, c’est-à-dire que l’attribution des points de données aux regroupements ne change pas.
L’approche suivie par -moyennes pour résoudre le problème est appelée Espérance - Maximisation (EM) qui se fait en deux étapes à savoir: le passage à l’Espérance et la Maximisation. En effet, l’étape de passage à l’Espérance consiste à affecter les points de données au regroupement le plus proche et l’étape de Maximisation calcule le centroïde de chaque regroupement. Vous trouverez ci-dessous une description de la façon dont nous pouvons le résoudre mathématiquement. Nous définissons la fonction objectif de la manière suivante:
où le poids si le point de données appartient au groupe , sinon, . De plus, est le centre de gravité du groupe .
La fonction objectif -moyennes est très populaire dans les applications pratiques du regroupement. Cependant, il s’avère que trouver la solution optimale des -moyennes est souvent irréalisable par le calcul (le problème est NP-difficile). Comme alternative, l’algorithme itératif simple précèdent est souvent utilisé, si bien que, dans de nombreux cas, le terme de regroupement des -moyennes fait référence au résultat de cet algorithme plutôt qu’au regroupement qui minimise le coût objectif des -moyennes.
K-moyenne: cas pratique¶
Veuillez Cliquer ici pour avoir un aperçu de cas pratique écrit en Python.
Réduction de dimension¶
Dans cette section, nous présenterons des méthodes ou algorithmes de réduction de dimension, à savoir, le positionnement multidimensionnel et l’analyse à composantes principales.
Positionnement multidimensionnel (MDS en Anglais)¶
Le positionnement multidimensionnel, plus connu sous le nom de Multi-Dimensional Scaling (MDS) dans sa version anglaise est, d’après wikipédia, un ensemble de techniques statistiques utilisées dans le domaine de la visualisation d’information pour explorer les similarités dans les données. Il contient principalement trois méthodes qui sont: le positionnement multidimensionel classique, le positionnement multidimensionel métrique et le positionnement multidimensionel non métrique.
Pour les données utilisées dans les sections précedentes, les points de données étaient caractérisés par leurs coordonnées dans l’espace affine associé. Cependant, il existe des cas où les coordonnées explicites des points de données ne sont pas disponibles mais plutôt les distances entre chaque paire de points. L’idée générale du positionnement multidimensionnel est la réduction de dimension comme dans le cas de l’analyse en composantes principales, mais ici, nous avons comme entrées, une matrice de similarité entre les points. De la matrice de similarité, nous essayerons d’obtenir les coordonnées des points de données et les répresenter dans un plan, un espace de dimension trois, ou plus (mais de dimension inférieure à la taille des données).
Dans cette partie, nous parlerons du positionnement multidimensionnel classique; pour les autres types de positionnement, le lecteur pourra se référer à la litérature Bishop (2006)Schiffman et al. (1981).
Supposons une matrice où représente la similarité entre les et exemples de données. Ce que nous avons à notre possession, c’est la matrice de similarité entre les exemples.
Dans le cas du positionnement multidimensionnel, la fonction de perte ou fonction de décision est appelée stress et elle est donnée par:
avec , et , les points obtenus aprés la réduction de dimension. De l’équation (2), nous pouvons remarquer que notre objectif principal est de trouver de telle sorte que: . Cette solution n’est pas unique, puisqu’à part le fait que soit solution, , l’est aussi.
En utilisant l’assomption de la configuration centrée qui stipule:
et en définissant la matrice de Gram par qui est une matrice carrée de dimension , avec , nous avons:
avec et .
Nous posons: $$\begin{align*} \label{T_expression}
T = \sum_{i}b_{ii} \end{align*}$$
En utilisant les relations (4) et T_expression, nous obtenons:
En utilisant la relation (4), l’équation (5) devient :
À partir des relations (3), (4) et (6), nous pouvons déduire :
avec :
,
,
.
L’[algorithme]{style=“color: blue”} de positionnement classique est donné comme suit:
Calculer la moyenne par rangées donnée par:
Calculer la matrice similaire à notre matrice de similarité et définie par:
avec , une matrice contenant que des 1 et de dimension . Ici, la matrice doit être semi-définie positive, ce qui signifie qu’elle doit avoir des valeurs propres positives ou bien égales à zéro. est une matrice ayant comme éléments .
Calculer les vecteurs propres et valeurs propres de la matrice .
La -ème coordonnée réduite pour l’exemple est
Le positionnement multidimensionnel est utilisé en analyse des préférences sur l’ensemble des domaines d’application de la psychométrie, en particulier dans la conception et le marketing des produits agro-alimentaires ici.
Analyse en Composantes Principales (ACP)¶
L’Analyse en composantes principales (ACP, PCA en Anglais) est l’une des plus célèbres méthodes de compression, réduction de dimensions et de visualisation de données. Elle utilise ce qu’on appelle composantes principales pour trouver une base du sous-espace sur lequel on projète les données. Pour mieux comprendre le fonctionnements de l’ACP, nous allons commencer par illustrer le cas des données de dimension . Ensuite on généralisera pour le cas de dimension . On considère dorénavant un ensemble de données où désigne le nombre d’élements de .
Cas ¶
Supposons qu’on a les données dans le plan . La compression consiste donc à projeter ces données sur un sous-espace de , de dimension . On sait qu’un sous-espace de dimension 0 est un point. Donc la compression en dimension détruira toutes les informations sur les données en les réduisant en un point. Nous n’avons donc d’autres choix que de compresser en dimension , c’est-à-dire projeter les données sur une droite vectorielle. Pourtant, il y a une infinité de tels sous-espaces. Cependant, nous voulons une compression ayant le maximum d’informations sur nos données. Comment choisir ce sous-espace?
La méthode ACP consiste à choisir ce sous-espace comme la droite maximisant la variance des projections de données. Le vecteur directeur de cette droite s’appelle première composante principale ou tout simplement composante principale . Le complété orthogonal de ce sous-espace est engendré par la seconde composante principale.
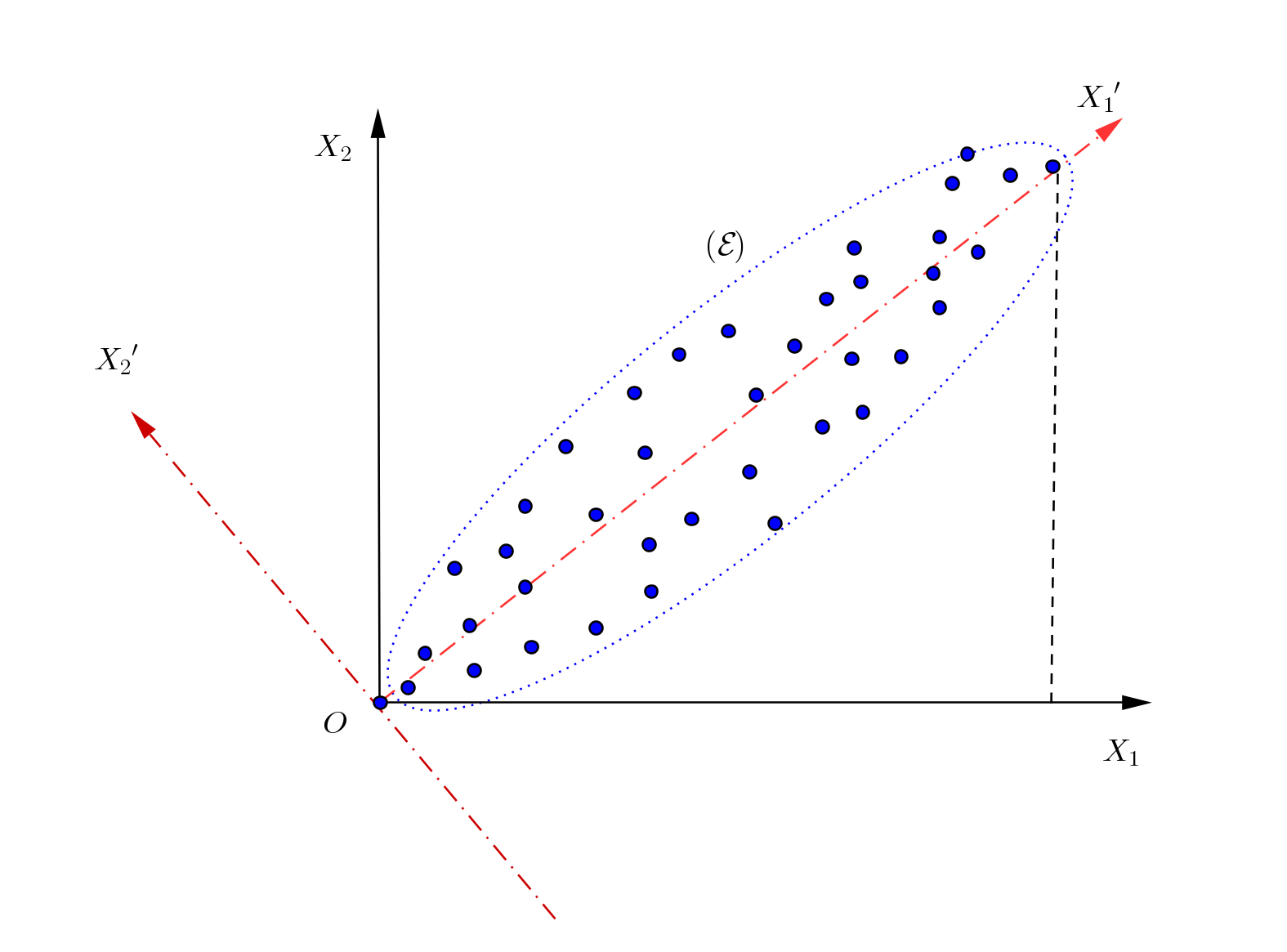
Figure 3:L’illustration de l’ACP
Dans la Figure 3, nous avons un ensemble de données dans un système de coordonnées . Supposons qu’on veux compresser l’ensemble de données dans un espace de dimension 1 qui peut être l’un des axes .
En projetant sur (resp. ), on obtiendra une représentation assez compressée de nos données. En fait, quelques représentations des points sont confondues.
En projetant sur les données sont projetées sur un segment de même longueur que le petit axe de l’ellipse . On obtiendra une représentation trop compressée des données. Tant d’informations sur les données sont donc perdues. Beaucoup de points auront la même représentation.
En projetant sur on voit que la représentation des points est "presque injective" [1]. C’est donc la représentation idéale pour notre exemple.
Dans notre cas, la première composante principale est le vecteur (unitaire) directeur de l’axe puisqu’il nous permet d’avoir le maximum de variance lors de la compression.
Cas général ().¶
Dans le cas , nous avons essayé de donner une explication intuitive et visuelle de ce que l’algorithme ACP fait. Dans ce qui suit, nous allons généraliser la méthode ACP. L’objectif principal de cette méthode est donc de trouver les composantes principales.
Comment trouver les composantes principales?
La méthode classique pour trouver les composantes principales est d’utiliser les valeurs propres et vecteurs propres de la matrice de covariances des données. La première composante principale n’est autre que le vecteur propre correspondant à la plus grande valeur propre, la seconde composante principale est celui qui correspond à la deuxième plus grande valeur propre, et ainsi de suite. En effet, on peut prouver que les vecteurs propres de la matrice des covariances donnent les directions sur lesquelles les données ont la variance maximale (voir Section 1.1 de Jolliffe (1986)).
Soit la matrice de covariance des données. Puisque les données sont de dimension , est une matrice carrée d’ordre (). Rappelons aussi que la matrice de covariance est symétrique définie positive. Donc les valeurs propres de sont toutes strictement positives.
Soient les valeurs propres de correspondant respectivement aux vecteurs propres . Sans perte de généralité, on peut supposer que les valeurs propres sont arrangées dans l’ordre décroissant, c’est-à-dire et que les vecteurs propres sont tous unitaires (de norme 1). Notons que ces vecteurs propres forment une base orhtonormée de .
Notons par les représentations des éléments de dans la base de . Pour compresser sur un espace de dimension (), l’ACP prend les éléments de et les tronque à la -ième composante.
Algorithme de l’Analyse en Composantes Principales.¶
Remarque. Avant de procéder à l’ ACP, il faut normaliser les données, en soustrayant la moyenne puis en divisant par l’écart-type, composantes par composantes. C’est très important parce que les composantes caractéristiques peuvent avoir différentes unités de mesure.
Algorithme: Voici les étapes de l’algorithme :
Calculer la moyenne :
Calculer la matrice de covariance
Trouver les valeurs propres et vecteurs propres:
Choisir les valeurs propres de plus grande valeurs:
Ranger les valeurs propres dans l’ordre décroissant
Choisir une valeur de tolérance .
Le nombre de valeurs propres choisies satisfera la relation
Choisir les vecteurs propres correspondants et noter par la matrice d’ordre formée.
Extraire les représentations en dimension en multipliant par les .
Applications¶
L’objectif généralement lorsque nous effectuons une analyse de regroupement:
Obtenir une intuition significative de la structure des données que nous traitons.
Grouper puis prédire, où différents modèles seront construits pour différents sous-groupes si nous pensons qu’il existe une grande variation dans les comportements des différents sous-groupes. Un exemple de cela est de regrouper les patients en différents sous-groupes et de construire un modèle pour chaque sous-groupe afin de prédire la probabilité du risque de crise cardiaque.
De ce fait, l’algorithme -moyenne étant très populaire peut être utilisé dans diverses applications telles que la segmentation du marche, le regroupement de documents, la segmentation d’images et la compression d’images, etc.
La classification de documents en plusieurs catégories en fonction des balises, des sujets et du contenu du document;
Optimisation d’un magasin de livraison, ceci en utilisant une combinaison de -moyens pour trouver le nombre optimal d’emplacements de lancements;
Identification des localités de crimes, ceci avec des données relatives aux crimes disponibles dans des localités spécifiques d’une ville, la catégorie de crime, la zone du crime et l’association entre les deux peuvent donner un aperçu de qualité des zones sujettes à la criminalité dans une ville ou une localité;
Segmentation de la clientèle tout en aidant les spécialistes du marketing à améliorer leur base de clients, à travailler sur des domaines cibles et à segmenter les clients en fonction de l’historique des achats, des intérêts ou du suivi des activités;
détection de fraude à l’assurance: en utilisant des données historiques passées sur les réclamations frauduleuses, il est possible d’isoler les nouvelles réclamations en fonction de leur proximité avec des grappes qui indiquent des modèles frauduleux;
Analyse des données de covoiturage: l’analyse de ces données est utile non seulement dans le contexte d’uber, mais également pour donner un aperçu des modèles de trafic urbain et nous aider à planifier les villes du futur;
Criminels de cyber-profilage en classifiant les types de criminels qui se trouvent sur des lieux de crime;
Regroupement automatique des alertes informatiques;
Classification de performance académique;
Moteurs de recherche: Les résultats de recherche sont groupés en utilisant l’algorithme de regroupement;
La segmentation ainsi que la compression d’images.
Conclusion¶
Dans ce chapitre, les données étaient considérées comme linéairement séparables, c’est à dire nous pouvons trouver une ligne droite (dans le cas où nous sommes en dimension deux) ou un hyperplan (de manière générale) qui sépare ces données. De plus la distance que nous avions considérée était celle Euclidienne. Cependant, dans la plupart des cas, nos données sont non-linéaires et la distance considérée peut être géodésique, c’est à dire non Euclidienne ou bien Riemanienne. Pour cela, nous devons nous référer à des méthodes ou bien des algorithmes qui nous permettent de pouvoir faire soit le partitionnement ou la réduction de dimension dans le dit cas et aussi considérer des cas de distance non Euclidienne. Il y a plusieurs modèles qui ont été dévelopés, parmi ceux-là, nous avons les méthodes de Kernel comme Kernel PCA, Kernel Clustering, réseaux de neurones et aussi ISOMAP, dans le cas de distance géodésique. Certaines de ces méthodes vous seront présentées dans le chapitre Les méthodes du noyau (Kernel methods).
Cela signifie que presque chaque point aura une représentation différente de celle d’un autre point.
- Bishop, C. M. (2006). Pattern recognition and machine learning. springer.
- Schiffman, S. S., Reynolds, M. L., & Young, F. W. (1981). Introduction to multidimensional scaling. Academic press New York.
- Jolliffe, I. T. (1986). Principal components in regression analysis. In Principal component analysis (pp. 129–155). Springer.